
DQN 알고리즘과 강화 학습의 이해
https://www.youtube.com/watch?v=S1Y9eys2bdg
이번 블로그 포스팅에서는 강화 학습의 핵심 알고리즘 중 하나인 DQN(Deep Q-Network)에 대해 알아보겠습니다. 지난 포스팅에서는 Q-테이블 방법을 사용하여 가치 값을 추정하고 원하는 행동을 찾아가는 방법에 대해 설명했습니다. Q-테이블 방법은 간단하면서도 잘 작동하는 방법이지만, 상태 공간이 큰 문제나 복잡한 문제에는 적합하지 않은 단점이 있었습니다. 이러한 문제를 해결하기 위해 테이블 대신 신경망을 사용하여 가치 값을 추정하는 DQN 알고리즘이 등장했습니다. 이번 포스팅에서는 DQN 알고리즘의 기본 개념과 작동 원리를 설명하고, 이를 통해 복잡한 문제를 어떻게 해결할 수 있는지 살펴보겠습니다.
DQN 알고리즘의 배경
Q-테이블의 한계

Q-테이블은 각 상태-행동 쌍에 대한 Q 값을 저장하는 표입니다. 이 방법은 상태 공간이 작을 때는 효과적이지만, 상태 공간이 커질수록 테이블의 크기도 기하급수적으로 증가하게 되어 메모리 사용량과 계산 시간이 급격히 증가합니다. 또한, 복잡한 환경에서는 모든 상태-행동 쌍에 대한 Q 값을 학습하는 것이 비현실적일 수 있습니다.

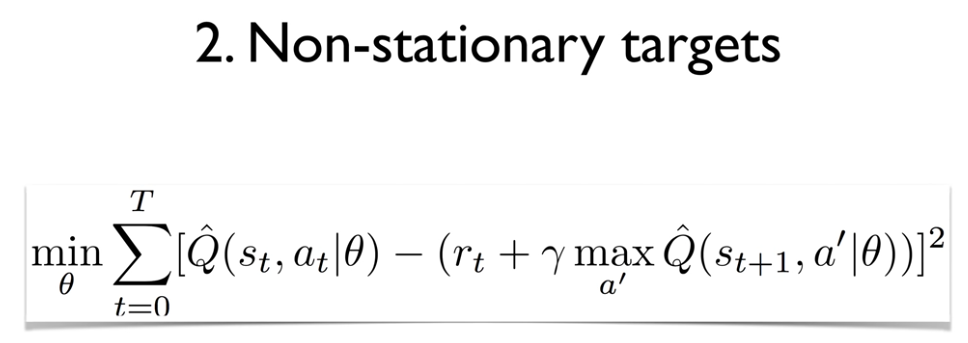
신경망을 이용한 가치 추정
신경망을 사용하여 Q 값을 추정하면, 모든 상태-행동 쌍에 대해 Q 값을 저장할 필요 없이 신경망이 상태를 입력받아 Q 값을 출력하도록 학습시킬 수 있습니다. 이를 통해 상태 공간이 큰 문제도 효과적으로 다룰 수 있습니다. 그러나, 단순히 신경망을 사용한다고 해서 모든 문제가 해결되는 것은 아닙니다. DQN 알고리즘은 이러한 문제를 해결하기 위해 몇 가지 중요한 기법을 도입하였습니다.
DQN 알고리즘의 핵심 기법




Experience Replay
DQN 알고리즘의 핵심 기법 중 하나는 Experience Replay입니다. 이는 에이전트가 경험한 데이터를 메모리에 저장하고, 학습할 때 무작위로 샘플링하여 사용하는 방법입니다. 이렇게 하면 학습 데이터가 시간에 따라 상관관계가 없어져서 더 안정적이고 효율적으로 학습할 수 있습니다.


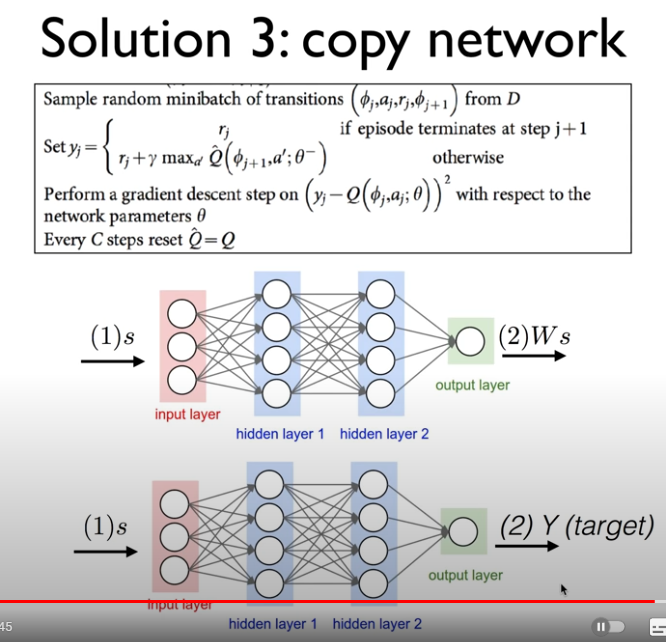
타겟 네트워크
DQN 알고리즘에서는 두 개의 신경망을 사용합니다. 하나는 현재 Q 값을 추정하는 메인 네트워크이고, 다른 하나는 목표 Q 값을 계산하는 타겟 네트워크입니다. 타겟 네트워크는 일정 주기마다 메인 네트워크의 가중치로 업데이트되므로, 목표 Q 값이 더 안정적으로 유지됩니다.




손실 함수와 업데이트
DQN 알고리즘의 손실 함수는 현재 Q 값과 목표 Q 값의 차이를 최소화하는 것입니다. 이를 통해 신경망이 더 정확한 Q 값을 추정할 수 있도록 학습합니다. 구체적인 업데이트 과정은 다음과 같습니다:
- 현재 상태에서 가능한 모든 행동에 대해 Q 값을 계산합니다.
- ε-greedy 정책을 사용하여 행동을 선택합니다.
- 선택한 행동을 환경에 적용하고, 다음 상태와 보상을 얻습니다.
- 경험을 메모리에 저장합니다.
- 메모리에서 무작위로 샘플을 선택하여 배치 데이터를 구성합니다.
- 현재 Q 값을 예측하고, 목표 Q 값을 계산합니다.
- 손실 함수를 최소화하도록 신경망의 가중치를 업데이트합니다.
DQN 알고리즘의 한계와 개선 방법
Overestimation Bias
DQN 알고리즘은 때때로 Q 값이 과대 평가되는 문제를 겪을 수 있습니다. 이는 행동 선택과 가치 추정이 같은 네트워크에 의해 수행되기 때문입니다. 이를 해결하기 위해 Double DQN(DDQN) 알고리즘이 제안되었습니다. DDQN은 행동 선택과 가치 추정을 다른 네트워크로 분리하여 과대 평가 문제를 완화합니다.
Prioritized Experience Replay
모든 경험이 동일하게 중요한 것은 아닙니다. 일부 경험은 학습에 더 큰 영향을 미칠 수 있습니다. Prioritized Experience Replay는 중요한 경험을 더 자주 학습하도록 메모리를 우선순위 큐로 관리하는 방법입니다. 이를 통해 학습 효율성을 높일 수 있습니다.
DQN 알고리즘의 실제 적용
DQN 알고리즘은 다양한 분야에서 성공적으로 적용되고 있습니다. 대표적인 예로는 게임 인공지능, 로보틱스, 자율 주행 등이 있습니다. 특히, DeepMind의 DQN 알고리즘은 Atari 게임에서 인간 수준의 성능을 달성하여 큰 주목을 받았습니다.
Atari 게임에서의 DQN
Atari 게임은 다양한 상태와 복잡한 행동을 포함하고 있어 강화 학습 알고리즘의 성능을 평가하기에 적합한 테스트베드입니다. DQN 알고리즘은 픽셀 단위의 상태 입력을 받아서 각 행동에 대한 Q 값을 출력하는 신경망을 학습시켜 놀라운 성과를 거두었습니다. 이는 DQN이 복잡한 환경에서도 효과적으로 학습할 수 있음을 보여줍니다.
자율 주행과 로보틱스에서의 DQN
자율 주행 차량과 로봇은 복잡한 환경에서 다양한 상황에 대응해야 합니다. DQN 알고리즘은 이러한 문제를 해결하기 위해 사용될 수 있습니다. 예를 들어, 자율 주행 차량은 도로 상황에 따라 최적의 운전 전략을 학습할 수 있으며, 로봇은 다양한 작업을 수행하는 데 필요한 행동을 학습할 수 있습니다.
DQN 알고리즘의 구현 예제
DQN 알고리즘을 실제로 구현해보면 그 작동 원리를 더 잘 이해할 수 있습니다. 아래는 간단한 DQN 알고리즘의 구현 예제입니다.
import numpy as np
import tensorflow as tf
from collections import deque
import random
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(24, input_dim=state_size, activation='relu'),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(action_size, activation='linear')
])
target_model = tf.keras.models.clone_model(model)
target_model.set_weights(model.get_weights())
def update_target_model():
target_model.set_weights(model.get_weights())
memory = deque(maxlen=2000)
gamma = 0.95
epsilon = 1.0
epsilon_min = 0.01
epsilon_decay = 0.995
batch_size = 32
def replay():
if len(memory) < batch_size:
return
minibatch = random.sample(memory, batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
target += gamma * np.amax(target_model.predict(next_state)[0])
target_f = model.predict(state)
target_f[0][action] = target
model.fit(state, target_f, epochs=1, verbose=0)
if epsilon > epsilon_min:
epsilon *= epsilon_decay
episodes = 1000
for e in range(episodes):
state = env.reset()
state = np.reshape(state, [1, state_size])
for time in range(500):
if np.random.rand() <= epsilon:
action = random.randrange(action_size)
else:
action = np.argmax(model.predict(state)[0])
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
memory.append((state, action, reward, next_state, done))
state = next_state
if done:
print(f"episode: {e}/{episodes}, score: {time}, epsilon: {epsilon:.2}")
break
replay()
if e % 10 == 0:
update_target_model()
이 예제는 간단한 CartPole 환경에서 DQN 알고리즘을 사용하여 최적의 정책을 학습하는 과정을 보여줍니다. 신경망 모델을 정의하고, 경험을 메모리에 저장한 후, 무작위 샘플링을 통해 학습하는 과정을 포함하고 있습니다. 이 코드에서는 경험 재생과 타겟 네트워크를 사용하여 안정적이고 효율적인 학습을 구현합니다.
결론
DQN 알고리즘은 강화 학습의 중요한 돌파구 중 하나로, 복잡한 상태 공간에서도 효과적으로 학습할 수 있도록 해줍니다. Experience Replay와 타겟 네트워크 같은 기법을 통해 학습의 안정성과 효율성을 크게 개선할 수 있습니다. DQN 알고리즘의 개념과 작동 원리를 이해하고, 실제로 구현해봄으로써 강화 학습의 강력함을 체험해 보시기 바랍니다.
태그: DQN, 강화 학습, 신경망, Experience Replay, 타겟 네트워크, 자율 주행, 로보틱스, 게임 인공지능, Atari, 딥러닝
'IT' 카테고리의 다른 글
| NVIDIA와 아리스타 네트웍스의 AI 데이터 센터 네트워크 인프라 경쟁 (0) | 2024.07.20 |
|---|---|
| 내가 더 이상 GitHub Copilot을 사용하지 않는 이유 : (지극히 개인적이고 주관적인!) 의견 공유해봅니다. (0) | 2024.07.20 |
| Lab 7-1: DQN 1 (NIPS 2013) 알고리즘 구현 (0) | 2024.07.20 |
| 구글의 천재 프로그래머 제프 딘 Jeff Dean (0) | 2024.07.19 |
| 일은 AI가 한대! 돈은 누가 벌래? 노코딩 자동화 툴 MAKE 완벽 튜토리얼 (0) | 2024.07.18 |



댓글