Q-러닝을 통한 강화 학습 실습: Frozen Lake 예제
이번 글에서는 Q-러닝(Q-learning)을 통해 강화 학습을 실습하는 방법을 소개합니다. 특히, Frozen Lake 게임을 예제로 사용하여 Q-러닝의 핵심 개념과 알고리즘을 이해하고, 이를 통해 에이전트가 최적의 경로를 찾아가는 과정을 살펴보겠습니다. Q-러닝은 강화 학습에서 매우 중요한 알고리즘으로, 상태-행동 쌍의 가치를 학습하여 최적의 행동을 선택할 수 있도록 합니다.
https://www.youtube.com/watch?v=Vd-gmo-qO5E
Q-러닝 개요
Q-러닝은 강화 학습에서 사용하는 대표적인 알고리즘 중 하나입니다. 이는 상태-행동 쌍의 가치를 학습하여 최적의 행동을 선택할 수 있도록 합니다. Q-러닝의 핵심 아이디어는 상태와 행동을 입력으로 받아, 해당 상태에서 특정 행동을 수행할 때 기대되는 보상을 출력하는 Q-함수를 학습하는 것입니다.
Q-러닝의 기본 개념
- 상태(State): 에이전트가 현재 위치한 환경의 상태를 나타냅니다.
- 행동(Action): 에이전트가 상태에서 취할 수 있는 행동을 나타냅니다.
- 보상(Reward): 에이전트가 특정 행동을 수행했을 때 받는 보상입니다.
- Q-함수(Q-function): 상태-행동 쌍을 입력으로 받아, 해당 상태에서 특정 행동을 수행할 때 기대되는 보상을 출력합니다.
Frozen Lake 환경 소개
Frozen Lake는 OpenAI GYM에서 제공하는 간단한 환경 중 하나입니다. 이 환경에서 에이전트는 얼음 위를 이동하여 목표 지점에 도달하는 것이 목표입니다. 얼음판에는 구멍이 있으며, 에이전트가 구멍에 빠지면 게임이 종료됩니다.
환경 설정
Q-러닝 알고리즘
Q-러닝의 주요 단계
Q-러닝 알고리즘은 다음과 같은 순서로 진행됩니다:
- Q-테이블 초기화: Q-테이블을 모든 상태-행동 쌍에 대해 0으로 초기화합니다.
- 에피소드 반복: 각 에피소드마다 상태를 초기화합니다.
- 행동 선택: 현재 상태에서 최적의 행동을 선택하거나 랜덤하게 선택합니다.
- 행동 수행: 선택한 행동을 환경에서 수행하고, 새로운 상태와 보상을 얻습니다.
- Q-값 업데이트: Q-값을 업데이트합니다.
- 상태 갱신: 새로운 상태로 현재 상태를 갱신합니다.
- 종료 조건: 에피소드가 종료되면 다음 에피소드를 시작합니다.
Q-값 업데이트 공식
Q-값은 다음 공식에 따라 업데이트됩니다:
Q(s,a)←Q(s,a)+α(r+γmaxa′Q(s′,a′)−Q(s,a))Q(s, a) \leftarrow Q(s, a) + \alpha \left( r + \gamma \max_{a'} Q(s', a') - Q(s, a) \right)
여기서,
- Q(s,a)Q(s, a)는 현재 상태 ss에서 행동 aa를 선택했을 때의 Q-값입니다.
- α\alpha는 학습률(learning rate)입니다.
- rr은 현재 상태에서 행동 aa를 선택했을 때의 보상입니다.
- γ\gamma는 할인율(discount factor)입니다.
- maxa′Q(s′,a′)\max_{a'} Q(s', a')는 다음 상태 s′s'에서 가능한 모든 행동 a′a' 중 최대 Q-값입니다.
Q-러닝 알고리즘 구현
예제 코드
다음은 Q-러닝 알고리즘을 사용하여 Frozen Lake 환경을 학습하는 예제 코드입니다:
import gym
env = gym.make('FrozenLake-v0')
Q = np.zeros([env.observation_space.n, env.action_space.n])
alpha = 0.1
gamma = 0.99
epsilon = 0.1
for episode in range(1000):
state = env.reset()
done = False
while not done:
if np.random.rand() < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(Q[state, :])
next_state, reward, done, info = env.step(action)
Q[state, action] = Q[state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[state, action])
state = next_state
print("Q-테이블")
print(Q)
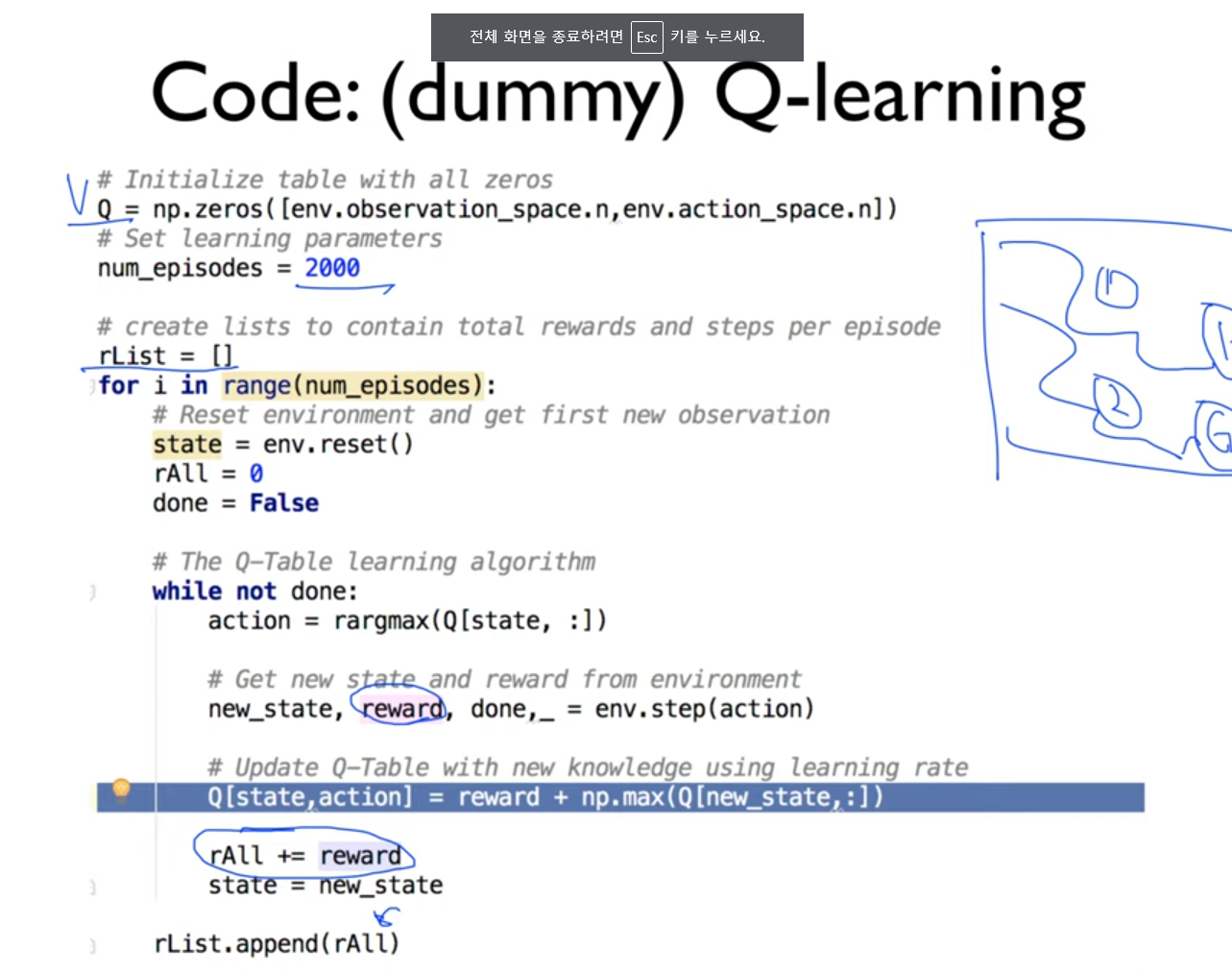
이 코드는 1000번의 에피소드를 반복하며 Q-테이블을 학습합니다. 학습이 완료된 후, Q-테이블을 출력합니다.

Q-러닝 실습: Frozen Lake 게임 플레이
게임 플레이 코드
학습된 Q-테이블을 사용하여 Frozen Lake 게임을 플레이해보겠습니다. 다음 코드는 학습된 Q-테이블을 사용하여 최적의 경로를 찾아가는 에이전트를 구현합니다:
env.render()
done = False
while not done:
action = np.argmax(Q[state, :])
next_state, reward, done, info = env.step(action)
env.render()
state = next_state
if done:
if reward == 1:
print("Goal reached!")
else:
print("Fell into a hole!")
break
이 코드는 학습된 Q-테이블을 사용하여 에이전트가 최적의 경로를 찾아가는 과정을 보여줍니다.
결론
이번 글에서는 Q-러닝 알고리즘을 통해 강화 학습을 실습하는 방법을 소개했습니다. Frozen Lake 게임을 예제로 사용하여 Q-러닝의 핵심 개념과 알고리즘을 이해하고, 이를 통해 에이전트가 최적의 경로를 찾아가는 과정을 살펴보았습니다. Q-러닝은 강화 학습에서 매우 중요한 알고리즘으로, 다양한 문제에 적용할 수 있는 강력한 도구입니다.
태그
강화학습, Q러닝, OpenAIGYM, 머신러닝, 인공지능, 프로즌레이크, 강화학습알고리즘, 자율주행, 로봇제어, 게임AI
'IT' 카테고리의 다른 글
| Lab 4: Q-learning을 활용한 Exploration and Exploitation와 할인된 보상 discounted reward 최적화 (0) | 2024.07.17 |
|---|---|
| OpenAI GYM 환경을 이용한 강화 학습 실습 (0) | 2024.07.17 |
| Q-러닝을 완벽하게 하는 방법 (0) | 2024.07.17 |
| Lecture 2: Playing OpenAI GYM: GamesOpenAI GYM 환경을 이용한 강화 학습 실습 (0) | 2024.07.17 |
| 모두를 위한 머신러닝/딥러닝 강의: 강화 학습 소개: 기초부터 응용까지 (0) | 2024.07.17 |
댓글